
Cinc maneres de llegir en línia i noves mètriques específiques per a articles de premsa
Des del frau i l’escaneig fins a la lectura (última), un nou treball de Nir Grinberg analitza les maneres de llegir en línia i presenta una nova mesura per predir el temps que els lectors s’adhereixen a un article. Grinberg, investigador de l’Institut Harvard de Ciències Socials Quantitatius, juntament amb el Laboratori Lazer de Northeastern, va examinar les dades de Chartbeat per a set webs diferents d’editors: un conjunt de dades de més de 7,7 milions de pàgines vistes, tant de mòbils com d’escriptori, de 66,821 articles de notícies des dels llocs. (Per protegir la privadesa de les editorials, no es nomenen en el document, però Grinberg va mirar un web de notícies financeres, un d’inici, un de notícies tecnològiques, un de notícies sobre ciències, un ldestinat a les dones, un d’esport lloc i un web de determinada revista).
Chartbeat, va dir Grinberg, ja ofereix als editors un bon seguiment. “És una de les poques empreses que fan un seguiment del què passa amb un usuari després de fer clic a un article de notícies”, em va dir. “Tot i així, les mesures reals que proporciona són una mena de matèria primera. Et dirà quant de temps ha passat una persona en una pàgina, fins a quin punt ha arribat de la pàgina, fins i tot l’anomenat “temps dedicat”, que és el nombre d’interaccions de la pàgina: clics del ratolí, moviment del cursor, etc.
Però tots aquests webs no estan especialment adaptats a les notícies; podrien contenir qualsevol altre cosa. “Grinberg va adaptar aquestes mesures en brut per crear noves mètriques específicament per a articles de notícies”.
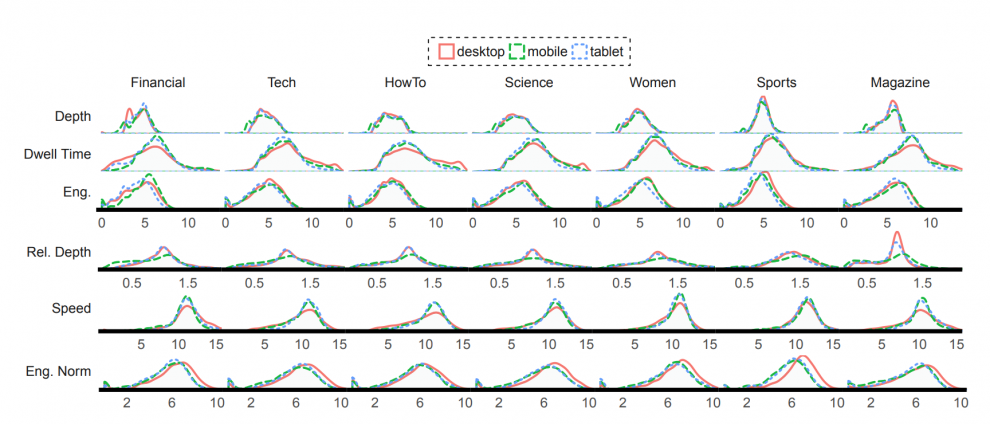
“En lloc de veure fins a quin punt la persona va ser al web, estic veient quin percentatge de l’article ha vist realment, i fins on va baixar la pàgina, en relació amb la durada de l’article, cal buscar més el detall. Si algú va dedicar molt de temps a un article i l’article és curt, això és un bon senyal. Si passessin la mateixa quantitat de temps en un article llarg, això ja fora menys bo”.
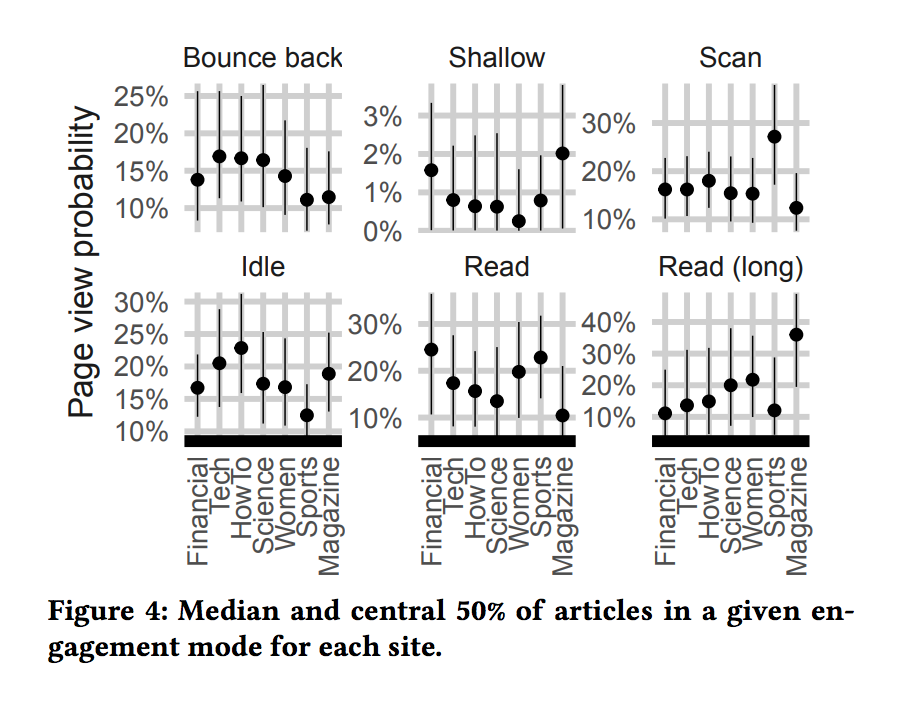
Grinberg va ser capaç d’identificar cinc tipus de comportaments de lectura: “Cercar”, “Llegir”, “Llegir (llarg)”, “Inactiu” i “Baix” (més rebots, en cas que algú arribi a una pàgina i gairebé en surti immediatament). No és sorprenent que diferents tipus de llocs de notícies vegin diferents tipus de comportament de lectura. En el web esportiu, per exemple, “veiem que hi ha molta cerca. Crec que el que passa és que molta gent acudeix als llocs d’esports per trobar un resultat, com el resultat d’un joc, i no llegeix res. Un altre exemple que es va destacar és el lloc de procediments, on veiem que hi ha més inactivitat; la gent llegeix un article, romanen inactius per un moment, i després continuen. A partir d’observar els articles en si, sembla que la gent segueix instruccions sobre com fer alguna cosa al món real”. Mentrestant, en el web de la revista, la gent sembla estar llegint durant períodes de temps llargs.
A la segona part del document, Grinberg identifica una mesura que ell anomena “guany d’informació semàntica” (SIG): una manera de “[capturar] el flux d’informació dins del text dels articles, i explica quelcom de la variabilitat en el camí la gent s’ocupa d’articles “. Grinberg va intentar explicar-me-ho:
Imagineu que el punt que un article està tractant de fer és un punt real de l’espai, diguem un punt sobre un paper. De la mateixa manera, cada paràgraf pot ser un punt en el mateix document. A mesura que considerem més i més paràgrafs (p1, p1 + p2, p1 + p2 + p3 +…), ens acostem més al punt final de tot l’article amb tots els seus paràgrafs.
SIG captura la rapidesa amb que un article es mou cap al seu punt final, passant per tots els punts del camí que fan els paràgrafs individuals. Per exemple, un article que s’obre amb un paràgraf abstracte pot contenir molta informació al principi i afegir-ne una mica més endavant al text. En canvi, una llista pot tenir una distribució més uniforme de la informació al llarg del text.
SIG pot ser útil per als editors, diu Grinberg, perquè acaba sent molt predictiva de com es relaciona algú amb un article, i haurien de considerar-ho al llarg de les altres mètriques seguides per empreses com Chartbeat. “No hi ha una solució única per a tots”, va dir. “El web de la revista va proporcionar molta informació per endavant, i constata que la gent encara participa en les lectures llargues. Per contra, per als llocs esportius i financers, sembla que la informació de retenció al començament s’inicia amb lectures més llargues. Però els editors podrien començar a mirar SIG mentre prenen decisions sobre estratègia i experimenten amb diferents estructures de la història per veure què funciona per al seu públic”.
Grinberg va presentar el document, “Identificació de modes de participació de l’usuari amb notícies en línia i la seva relació amb l’obtenció d’informació en el text”, la setmana passada a The Web Conference de Lió, França.
Mediàtic/Àmbit d’Estratègia i Comunicació us ofereix íntegre aquest document si CLIQUEU AQUÍ
Per: Nieman Lab
Font Imatge: expertbeacon.com

